iRODS for managing next gen sequencing data in an HPC environment
Tue, 2011-05-03 11:59 | by Samuel LampaMy work in the UPPNEX project at UPPMAX HPC Center includes helping develop/find a solution to Next Generation Sequencing data management. The main aim is to automat data handling and making data handling easier for users.
One of the main challenges is how to handle all this data in a multiple projects/users environment where access restrictions are critical, while many users also want to share certain data, etc.
Jonas Hagberg found out about iRODS, which after some initial research seems to fit our needs very well. It also now seems to be what some big sequencing centers are focusing on right now (Sanger, Broad ...).
Basically, iRODS is a rule-oriented data management system, that sits as a logical layer on top of actual file systems, provides a unified file identifier namespace, and can automate things like data migration between fast cache-like storage and longer time archiving storage, meta data tagging etc. (or, the automation itself can be controlled by manual tagging). Client access is done via the shell through the i-commands, via a web-file manager interface, fuse module, Java or PHP API. All in all, iRODS looks surprisingly mature, and to provide good flexibility while keeping the tech-stack reasonably simple.
The Sanger iRODS slides (March 2011) were very good indeed (they much describe the problems that we face). Also there seems to be some slides (April 2011) from a corresponding initiative at Broad Inistitute.
Installation of iRODS on ubuntu is mainly executing an automated shell script, and is done in a few minutes, so I expect to be diving into iRODS rather full time from now on.
Some iRODS Links:
- iRODS Website
- iRODS Fact sheet
- iRODS Primer - Comprehensive guide to (seemingly) all you need to know
- Update: See also a very interesting article in Bio-IT World
Installing PDT 2.2 with XDebug 2.1.1 on Eclipse Helios on Ubuntu
Mon, 2011-04-11 20:03 | by Samuel Lampa(To be improved... got problems with image upload at the moment ... :/ )
After one year of very little PHP / MediaWiki / SMW coding, the time finally has came to get going a bit agian. So first thing was getting a decent PHP IDE with a debugger, up running.
Last year I used Eclipse with PDT (PHP Development Tools) and Xdebug. The installation was a bit tricky though and I had to stay with Eclipse Galileo due to some bugs, but now things have changed. With PDT 2.2 and the latest XDebug (2.1.1), installing on Ubuntu is a snap.
This is what should work:
Installing ArgoUML-Python for python code generation from UML
Mon, 2011-04-04 14:01 | by Samuel LampaI've been looking into ways to generate python code from UML. I tried Enterprise Architect from Sparx systems, which is indeed an impressive product, but since the code generation lacked features I wished for anyway, I thought looking into the open source alternatives might be worth it.
I tried some UML tools like Umbrello, Gaphor, StarUML etc but they all were either not mature enough, or had problems running on Linux or Linux/Wine.
I finally settled on ArgoUML, which feels mature enough. And there is the ArgoUML-python plugin, for python code generation (see also this question on StackOverflow, for a background to my choice). Unfortunately there is no binaries available for download, so you have to build them yourself. That was not much of a hassle at all in Eclipse though, so I'll go through the steps here:
A graphical client for running bioinformatics tools on HPC clusters
Thu, 2011-03-03 17:03 | by Samuel LampaThis blog has been silent for a while and someone might wonder what I've been doing.
One answer is: Developing a graphical client for non-linux-experienced users to connect securely to a computer cluster and configure batch jobs for common bioinformatics software. The project is financed within the UPPNEX project, and so the focus is foremost analysis of Next Generation Sequencing data, but the client will be fully capable to use for any software installed on the cluster.
The client meets a rising need in the next generation sequencing community, since biologists generally have far less experience with *nix systems and programming, than, say physicists, while the vast amounts of sequencing data increases the need to use large scale computing resources such as the ones provided in the UPPNEX project.
I demonstrated a proof-of-concept version at the UPPNEX-SciLifeLab bioinformatics forum on Feb 22nd, and the slides are now available:
As can be seen in the slides, the client is based on the very capable Bioclipse platform.
Repository of scripts for Next Generation Sequencing (NGS) at UPPNEX
Mon, 2011-01-31 17:50 | by Samuel LampaThe other day we set up a repository at the UPPNEX website, for typical workflows/scripts, used for mangling Next Generation Sequencing data at the SNIC-UPPMAX HPC clusters. Only two scripts there so far, but we are expecting more to come!
We were discussing different solutions for such a repository, including sites like gist.github.com and www.myexperiment.org, but settled for an own repository in order to provide maximally convenient access for the not-always-so-computer-mileaged NGS community. We'll encourage users to also publish their scripts on sites like myexperiment.org though (Actually, that kind of publicity should be a good thing in general for UU).
Looping over a List<String> in Bioclipse's JS console
Mon, 2011-01-31 17:19 | by Samuel LampaI had some trouble finding out how to loop over the results of a manager method in Bioclipse, which returns a List<String> to Bioclipse's javascript console. Since I didn't find it documented anywhere (probably it is, somewhere?), I wanted to ducument the snippet here:
var strings = myManager.methodReturningListOfStrings(someParams); for (var i=0; i<strings.size(); i++) { js.say(strings.get(i)); }
Operator and Bracket Syntax in PyDev
Mon, 2011-01-17 14:12 | by Samuel LampaLoving the new operator and bracket syntax highlighting in PyDev for Eclipse! (I installed it from the nightly builds Eclipse Update site, as it is included in the upcoming 1.6.5 only). See screenshot below for my favourite highting Scheme (creds: Rolf Lampa):

Eric Python IDE vs PyDev for Eclipse
Tue, 2010-12-28 15:54 | by Samuel Lampast discovered the Eric Python IDE, and I have to say I'm impressed.
I have been using PyDev for Eclipse so far, but was annoyed by the lack of options for the syntax highlighting, leaving me with rather sparingly colored code, which I found a bit hard to read at times. With Eric, I could configure up my favourite scheme (for which the cred goes to Rolf, my father :) ).
I have put the screenshots of my PyDev highlighting scheme, and the Eric one, below, so you can have a look for yourselves:

Eric Python IDE:
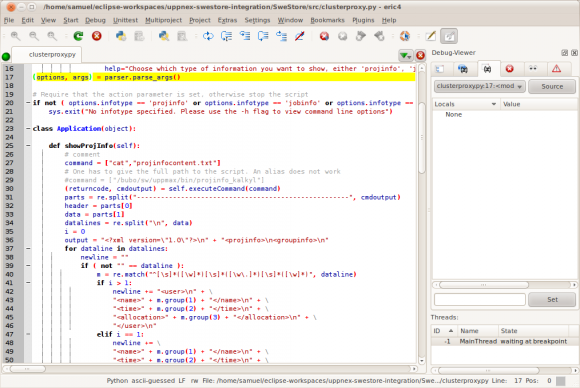
I will see soon which IDE I finally ended up using, but so far Eric seems to be the favourite ...
UPDATE: I have now found that Eric IDE lacks code navigation facilities (aka "Go to definition"), which makes it rather useless for my object oriented projects, where lots of code happens away in object methods...
UPPNEX web portal is live!
Wed, 2010-11-10 11:58 | by Samuel LampaUPPNEX's new web portal is now live!
- Visit: https://www.uppnex.uu.se
UPPNEX is a new initiative at Uppsala University, (lead by it's High Performance computing center SNIC-UPPMAX), to provide storage and high performance data analysis resources to the vibrant Next Generation Sequencing community in the Stockholm/Uppsala region and Sweden as a whole (some of the many recent projects was recently published in Nature).
This initiative is thought as a resource for wet-lab researchers with limited computer experience, and so it was important to provide with a one-stop place were these users can go to find documentation, information and contact to support staff. A website needed to be built.
Jonas Hagberg, system expert at UPPMAX and lead of the UPPNEX project, built up the site, created the current theme as a modification from the sky theme, and created the overall structure. I did - as currently working at Uppnex - come in at the later stage and created some graphics, the logo (in close collaboration with Jonas) and some additional configurations.
Swedberg lecture: Trying to survive the data deluge: bioinformatics tools for analyzing and visualizing large data samples
Mon, 2010-10-11 16:23 | by Samuel LampaDr. Reinhard Schneider from the European Molecular Biology Laboratory held a lecture at BMC in Uppsala with the title seen above. It seemed quite relevant to the stuff I'm currently doing at Science for Life Laboratory (where I'm employed for 2 months), investigating LIMS systems for NextGen sequencing data, as well as learning about analysis tools in the area.
What Reinhard presented was four different tools that they have developed/are working on, which tries to solve some of the problems of grasping heterogenous data sources. From the lecture info:
Recent blog posts
- I created a Udemy course on my favourite linux commandline productivity techniques
- My top-languages-per-use-case list
- The smallest pipeable python script
- Vote for ProcessWire to be packaged as a BitNami image
- Calling Java from Python without the JVM startup latency: NailGun and JPype
- New Google+ communities: Bioclipse, Cheminformatics, Semantic MediaWiki
- Don't use Swedish keyboard with vim/screen/bash
- Easier debugging of Go programs on the command line with CGDB
- Profiling and creating call graphs for Go programs with "go tool pprof"
- Python-like generator functions in Go