Samuel Lampa's blog
First look at code - Thoughts and questions
Thu, 2010-05-13 17:45 | by Samuel LampaCoding for my GSoC project will start for real in June, 9th or so, but I just had a first look at code, to start wrapping my head around the things involved. I installed the following on my local SMW:
I tested the RAP based SPARQL endpoint, played a bit with SMWWriter, and tried to get some grips of how to best use existing functionality for implementing RDF import/export.
Some questions that arose (for Denny in the first place, I guess, but feel free to comment):
- For implementing a SPARQL endpoint, should the ARC RDF store be implemented, similar to how RAP implements a separate store that mirrors the content in the SMW, or is there any way to get around the need for an extra store?
- An alternative starting point to implementing an ARC store, In addition to the RAP store connector already available in SMW, seems to be the JosekiStore connector in SparqlExtension. But of course, one can look at both.
- Where to find the relevant functionality related to the equivalent URI property found? In SMW_Exporter.php? other places too?
- SMWWriter depends on an outdated version of PageObjectModel, while the latter
seems to have stabilized (no changes since 2008). What to do about that?
Playing with SMWWriter
Thu, 2010-05-13 16:53 | by Samuel LampaWe are probably going to use SMWWriter for extending the RDF import/export functionality of Semantic MediaWiki, so I wanted to test it out a bit.
With some copy and paste of code from this page, I quickly had a MediaWiki Special Page set up, where I could make use SMWWriters internal API to implement a crude form for adding or removing "triples" in my Semantic MediaWiki. See Screenshot:
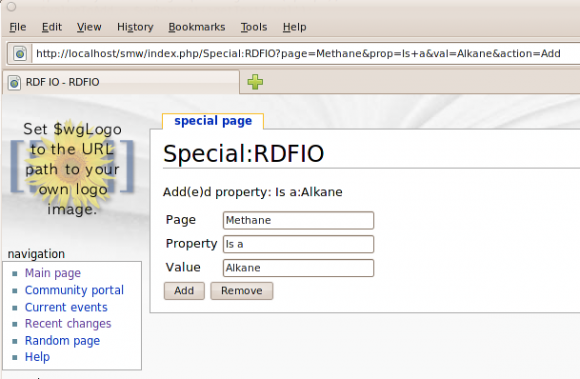
And the result, on the Methane page:
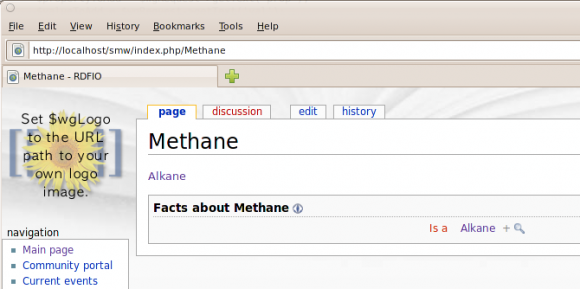
Looks promising. Connecting this with some ARC functionality for parsing SPARQL and RDF/XML, should make a big step in the right direction.
Testing set up of SPARQL endpoint for SMW using RAP and NetAPI
Thu, 2010-05-13 04:25 | by Samuel Lampa(For my internal documentation, mostly)
Got Eclipse for PHP up running with XDebug
Thu, 2010-05-13 04:23 | by Samuel LampaGot Eclipse for PHP up running now, with XDebug. Yay :) It was a snap to install on my Ubuntu box. I basically followed this and this blog post. (The Ubuntu package for XDebug is php5-xdebug).
The Eclipse dialogs had changed location and structure a little, so for my documentation, I included a screenshot of the dialog under "Run > Debug configurations" below.

NSF soon requiring data management plans
Wed, 2010-05-12 19:24 | by Samuel LampaInteresting: "Scientists Seeking NSF Funding Will Soon Be Required to Submit Data Management Plans". Is this a new trend? If so, it should be an area where Bioclipse can help, I gues, not least through the planned ability to export semantic data to a Semantic MediaWiki (That will require me to finish my GSoC first, though).
Prolog query much faster when mimicking SPARQL
Sat, 2010-05-01 21:20 | by Samuel LampaI reported earlier that Jena/SPARQL outperformed Prolog for a lookup query with some numerical value comparison. It later on turned out that the results were flawed and finally that Prolog indeed was the fastest as soon as turning to datasets with more than a few hundred peaks.
The Prolog program I was using was rather complicated with recursive operations on double lists etc. Then, some week ago, I tried, in order to highlight differences in expressivity between Prolog and SPARQL, to implement a Prolog query that mimicked the structure of the SPARQL query I used, as close as possible. Interestingly it turned out that this Prolog query can be optimized to become blazing fast by reversing the order of shift values to search for, so that the largest values are searched for first. With this optimization the query outperforms both the SPARQL and the earlier used prolog code. See figure 1 below for results (The new prolog query is named "SWI-Prolog Minimal"). It appears that the querying time does not even increase with the number of triples in the RDF store!
 Figure 1: Spectrum similarity search comparison: SWI-Prolog vs. Jena
Figure 1: Spectrum similarity search comparison: SWI-Prolog vs. Jena
The explanation seems to stem from the fact that larger NMR Shift values are in general more unique than smaller values (see histogram of shift values in the full data set in figure 2 below). Thus, by testing for the largest value first, the query will be much less prone to get stuck in false leads. (Well, looking at the histogram, it appears that one could in fact do even better sorting than just from larger to smaller, like testing for values around 100 before values around 130 etc.)
 Figure 2: Histogram of NMR Shift values in 25000 spectrum dataset
Figure 2: Histogram of NMR Shift values in 25000 spectrum dataset
Automatically abbreviate authors first names in bibtex
Fri, 2010-04-30 17:12 | by Samuel LampaI had all my references (50+) with all author names spelled out, but was told to abbreviate first names to one letter (Indeed that looks better IMO too). I didn't want to do that manually, and found out that this can automatically be done by using the bibtex style "abbrv". So I set it in my latex document with
\bibliographystyle{abbrv} GSoC Project accepted
Tue, 2010-04-27 00:59 | by Samuel Lampa.png)
Just got to know that my proposed GSoC 2010 project: "General RDF export/import in Semantic MediaWiki" (as documented here), was accepted! That's some good news! :). Mentor will be Denny Vrandečić from the Semantic MediaWiki community.
Surely the project is going to be a challenge but it is a highly motivating one so I'm much looking forward to it, to hopefully, together with my mentor and the community, to solve things, and to learn a lot.
I posted a (slightly shortened) copy of the project proposal and my bio here.
The project will be continuously documented here on this blog, so keep an eye here if you are interested (Use the GSoC2010 tag to filter out relevant posts). Community discussion will likely happen at the SMW-Devel mailing list, and if you want to contact me directly, you can do that at samuel dot lampa at gmail dot com or skype samuel_lampa.
My current status/schedule is:
- This week: Very busy, finishing thesis report.
- Next 2 weeks (though starting a little this week): Get dev. environment up running (leaning towards Eclipse with PDT) and looking at code
- 12/5: Briefing with Denny
- Up until 9th: Very busy period with exams on 24/5 and 8/6.
- On 9th: Start coding! (So coding start will be a little delayed, but will make up for that no worries! :) (not to used to having spare time anyway))
GSoC Proposal: "General RDF export/import in Semantic MediaWiki"
Tue, 2010-04-27 00:56 | by Samuel LampaThis is a slightly shortened version of the full Proposal, iniially posted on my user page on MediaWiki.org, and then in final form on the GSoC app site.
Browse semantic data in parallell
Mon, 2010-04-26 23:24 | by Samuel LampaThe semantic web field has seemed quite void of successful general user interfaces to browse semantic data in an efficient way (SPARQL querying is not really for everybody and their aunt). An interesting approach is the Freebase Parallax which lets you continuously views sets of data all while you narrow down or extend your search criteria, thus "browsing in parallell". Seems to make a lot of sence in its simplicity.
Recent blog posts
- I created a Udemy course on my favourite linux commandline productivity techniques
- My top-languages-per-use-case list
- The smallest pipeable python script
- Vote for ProcessWire to be packaged as a BitNami image
- Calling Java from Python without the JVM startup latency: NailGun and JPype
- New Google+ communities: Bioclipse, Cheminformatics, Semantic MediaWiki
- Don't use Swedish keyboard with vim/screen/bash
- Easier debugging of Go programs on the command line with CGDB
- Profiling and creating call graphs for Go programs with "go tool pprof"
- Python-like generator functions in Go