Semantic MediaWiki
RDFIO 0.3.0 released
Fri, 2010-07-30 04:54 | by Samuel LampaI just created a new release of the RDFIO MediaWiki extension. A somewhat detailed list of the changes can be found in the change log. The relevant links:
The filter by ontology / vocabulary feature
New for this release is a "export by ontology" feature, that - when possible - restricts the URIs used for a wiki page to only those that appears in an ontology that the user points to. To give an idea of this feature see the following screenshot:
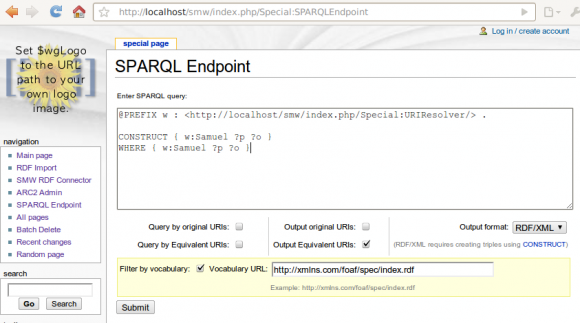
On the page "Samuel", I have one fact:
[[has blog::http://saml.rilspace.org]]
... and on the page "Property:has_blog", there are a number of facts, including:
[[Equivalent URI::http://xmlns.com/foaf/0.1/weblog]]
[[Equivalent URI::http://example.org/ExampleOntology/weblog]]
Current GSoC status
From the "remaining TODO list" from my last blog post, the following are finished with this release:
- In the SPARQL endpoint, enable querying by any URI specified as equivalent URI
- For RDF export, implement an "export by ontology" option, that - when possible - restricts the URIs used for a wiki page to only those that appears in an ontology that the user points to.
The remaining items ones are now:
- Create an HTML interface for interactively configureing how wiki titles should be chosen for RDF entities for which no preferred "wiki title property" (such as rdfs:label, dc:title etc.) was found.
- Add "pseudo namespaces" as an option for choosing wiki titles from general RDF URIs (not only properties!). I.e, the possibility to abbreviate a part of an URI into a pseudo-namespace, making the URI more fit for use as wiki title. (For properties, there if often a well known abbreviation for the corresponding vocabulary/ontology's base URI, but this is often not the case for general RDF entities, which can often be from some user defined data etc).
- If time permits:
- Implement filter by "export rdf" property.
New release of RDFIO (0.2.0) with security fixes
Thu, 2010-07-22 02:08 | by Samuel LampaJust to inform that I created a new release of the RDFIO MediaWiki extension. It contains important security fixes, by adding at least some basic checking of user rights and CSRFs (Cross site request forgeries) to the SPARQL endpoint, RDF import form etc. Thus, it's highly recommended to upgrade if you are using the extension on a public wiki!
- Download tarball
- Svn repo url: http://smwrdfio.googlecode.com/svn/branches/0.2.x
- Install instructions
Also, you might already have seen:
Current GSoC status
Otherwise, me and Denny just confirmed the remaining TODO list for my GSoC project, which is what I start working on now:
- In the SPARQL endpoint, enable querying by any URI specified as equivalent URI
- For RDF export, implement an "export by ontology" option, that - when possible - restricts the URIs used for a wiki page to only those that appears in an ontology that the user points to
- Create an HTML interface for interactively configureing how wiki titles should be chosen for RDF entities for which no preferred "wiki title property" (such as rdfs:label, dc:title etc.) was found.
- Add "pseudo namespaces" as an option for choosing wiki titles from general RDF URIs (not only properties!). I.e, the possibility to abbreviate a part of an URI into a pseudo-namespace, making the URI more fit for use as wiki title. (For properties, there if often a well known abbreviation for the corresponding vocabulary/ontology's base URI, but this is often not the case for general RDF entities, which can often be from some user defined data etc).
There are also some extra additions that I'll look into if time permits, like adding support for filtering the output on export with a property such as "RDF export::False", as suggested by Daniel Herzig.
Screencast: Installing Semantic MediaWiki and RDFIO from scratch on Ubuntu
Sat, 2010-07-17 01:48 | by Samuel LampaIn a previous blog post I demonstrated with a screen cast the RDFIO extension for Semantic MediaWiki but nothing on installation.
By testing I realized that the install procudure was VERY painful. I have now (with much valuable help from Oleg Simakoff) corrected a number of errors in the instructions and the code, and added to the install instructions commandline snippets for linux/ubuntu. I also created a screencast which goes through the steps from scratch (except Apache/MySQL/PHP setup), in a little more than 5 minutes. Hope this makes things easier for you testers! (And as you might try it out, please report any bugs or issues in the issue tracker!)
Sorry for the low volume level! Didn't realize that while recording ... :/
Screencast: RDF Import and SPARQL "Update" in Semantic MediaWiki
Fri, 2010-07-16 19:41 | by Samuel LampaSo, for those of you who might think the Install instructions for the RDFIO Semantic MediaWiki extension I'm working on are a bit daunting but would like a glimpse of what my GSoC project is up to anyway, I created a short (3:20) screencast demonstrating (ARC2 based) RDF Import and SPARQL "Update" functionality for some example data. (Sorry for the lame speaking ... :P ... didn't sleep for a looong time )
The screencast shows how you can import RDF/XML into Semantic MediaWiki and then use the SPARQL endpoint to insert or remove data to/from articles, even using the original format of the RDF that you imported earlier.
(For you who decide to try to install, please have a look at the error fixing happening in this thread.)
GSoC status update July 14
Wed, 2010-07-14 12:03 | by Samuel Lampa(Figured I better do regular status updates, as a lot of small things tend to get missed if blogging only when there is something to show off)
As you might have seen among the GSoC2010 tagged posts I've had a rudimental RDF/XML import, and a SPARQL endpoint (only for querying so far!) up running for a while. You should be able to set up these yourself by following one or more of the instructions in the Google code repo:
- ARC2 Store Install (required for SPARQL endpoint)
- ARC2 SPARQL Endpoint Install
- RDF Import Install
I have since worked a bit on some use cases, which revealed a lot of intricacies to take into account on RDF import. One of them was a spinoff discussion, from a blog post by Egon Willighagen, which quite nicely outlines one of the motivations for having general RDF import in MediaWiki (read post, read discussion).
The last few days I've been working on heavly refactoring the import code, so that it is more general and easy to modify in new ways. There is still a lot to be improved in the code, like error handling, documentation, adding more options etc, so feel free to give feedback on the code! (Especially RDFImporter.php and EquivalendURIHandler.php, and preferrably use the mailing lists: semediawiki-devel, semediawiki-user or mediawiki-l)
The RDF import seems to be the most challenging part in my project (and on which the export feature heavily depends) - since it is the part where I'm breaking a bit of new ground, so here feedback is much welcome.
Choosing wiki titles for RDF entities on import - Feedback wanted
The one most challenging issue is about how to select reasonable wikititles to use for RDF entities on RDF import, based on the RDF data (one relevant blog post here). The question of being able to export the page with the original URI, should not limit the choice directly, since this is already solved by storing the original URI as a property on each page.
The thoughts we have had so far - in short - is:
- First look if the RDF entity in question has one of a list of properties, in prioritized order, that should be used as wiki title.
- The first of these, could be a special property which can be used to manually specify this by including it in the imported RDF, like "hasWikiTitle".
- The suggested list or properties so far can be seen in this blog post. This list should of course be configurable, and one question is also how to best implement this configuration? A setting in LocalSettings.php? A wiki page?
- If no matching property is in this list, then the label for the RDF entity should be used. For example, if the entity:s URI is http://bio2rdf.org/go:0032283, then 0032283 is used.
How to configure namespace prefixes / preudo-namespaces?
Using only the label of course has the risk that multiple RDF entities converts to the same wiki title, which is not acceptable for example if using the wiki as a "one time RDF editor", which is one of the motivations for this project.
To solve this, one alternative (as a configurable option) could be to use a pseudo-namespace in the wiki title (e.g. "go" in the above example, which would result in "go:0032283" as the wikititle). This could be configured by creating a mapping between base URI:s and pseudo-namespaces (.e. "http://bio2rdf.org/go:" and "go", in this case).
But then there is the question how to configure this mapping. We've been thinking of a few options:
- Let it be configured in the incoming RDF, by using a custom predicate "hasPseudoNameSpace"
- Store a config in a Wiki article
- Config in LocalSettings.php
- On submitting data for import, analyze it first and present a screen with all the base URI:s used, with fields to manually fill in the pseudo-prefixes to use.
- Any combination of the above
I will be working ahead, and try to figure out the most reasonable strategy together with Denny (who is my GSoC mentor), but feedback and comments are always welcome! (As said, preferrably send feedback on the mailing lists; semediawiki-devel, semediawiki-user or mediawiki-l!)
If you want to follow the project progress, see the status page for options
RDF properties to use for wiki titles on import - suggestions?
Wed, 2010-06-30 11:20 | by Samuel LampaOne of the things we try to do in my GSoC project is to select suitable wiki titles when importing arbitrary RDF triples into Semantic MediaWiki (The full RDF URI:s are very ugly to use as wiki titles!).
Simply shorting the namespace in the entitiy's URI to it's prefix (as specified in the import data) could be a general fallback (see screenshot) but for many types of data it could be nice to make use of a property that puts some "natural language" label for the entity instead. We came up with this list of properties so far:
- http://semantic-mediawiki.org/swivt/1.0#page
- http://purl.org/dc/elements/1.1/title
- http://www.w3.org/2004/02/skos/core#preferredLabel
- http://xmlns.com/foaf/0.1/name
More suggestions?
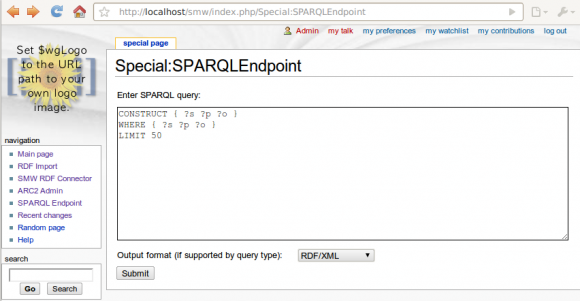
ARC2 based SPARQL Endpoint for Semantic MediaWiki up running
Tue, 2010-06-29 22:25 | by Samuel LampaI now managed to create a SPARQL endpoint for Semantic MediaWiki, in a MediaWiki SpecialPage, based on the ARC2 RDF library for PHP (including its built-in triplestore). See screenshot below, and code in the svn trunk. (I have to say I'm impressed by the ease of working with ARC2!)
Code is still quite ugly and the "Equivalent URI" handling that we talked about is still not implemented. Will turn to that now, while doing some refactoring (more object oriented etc).
Even nicer with more prefixes
Mon, 2010-06-28 14:58 | by Samuel Lampa
Ok, even nicer now ... after allowing to introduce custom namespace prefixes also with '?' and '=' as separators (Don't know if that is valid for QNames though? Anyone knows?) than before (blog post 1, and post 2):
Code (see code repo) is still quite ugly though. Just typed together to get things working. Will look at structuring things more as soon as I have slept a little better :)
I also got to think of these random issues, which is foremost questions to myself, that might not be fully thought-through yet, but jotting them down here for possible feedback (hoping it's readable ^^):
- Imports will have to be done according to a special "mapping configuration", so that the same config can be used on import and export, if wanted. Such a config should be generated on import based on the RDF namespaces used. It should also be manually expandable with a prioritized list of properties (like dc:title) to use as substitute for URIs. Maybe it could be stored in a (timestamped?) wiki article?
- When using "natural language" substitutes for URI:s, such as "dc:title", one has to put a property such as swivt:originalURI or similar into the page, so that it can be exported again with its original URI (or there is already the swivt:importedFrom (or sth like that...) ... is it better to use that?
- The SPARQL endpoint will need to be accessed according to the same kinds of mapping configs if the wiki should be able to be queried in the same format as the import data ...
Using RDF namespace prefixes in wiki titles
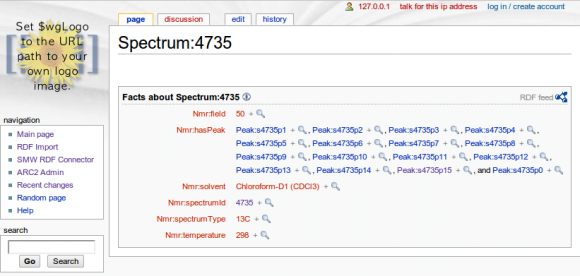
Mon, 2010-06-28 11:39 | by Samuel Lampa
As you might have seen in my previous blog post, using the full RDF URI:s as wiki titles on importing, is not optimal. I now managed to use the RDF namespace prefixes submitted on import time, to make titles nicer. Definitely improves things a bit. At least all properties are not all treated as the same as in the previous blog post for example.
But, also still a bit to go. Not all URI:s have prefixes, and for some things you would probably want to use the corresponding dc:title or similar instead of an abbreviated URI, etc.
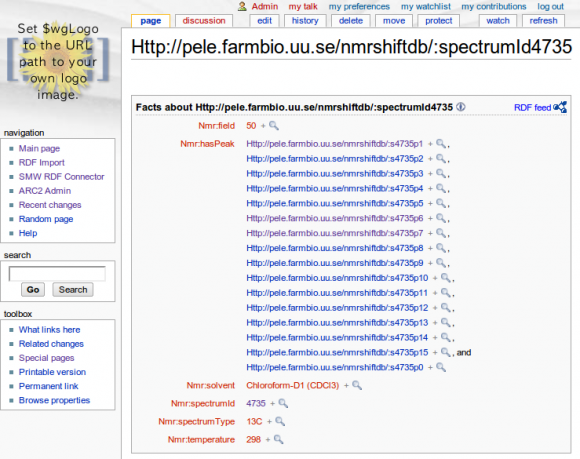
Populating SMW from RDF/XML (First test)
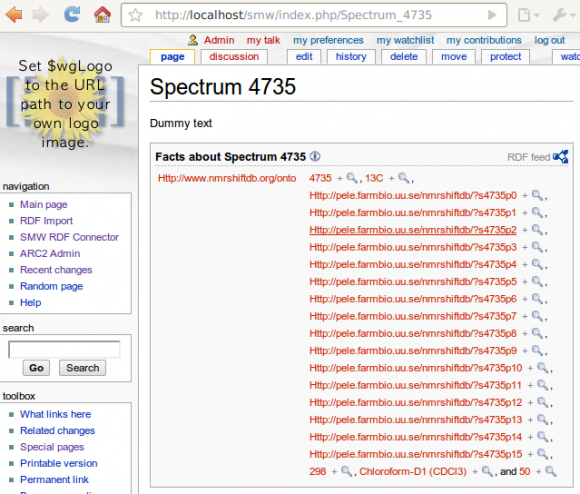
Sat, 2010-06-26 10:23 | by Samuel LampaI now managed, (using ARC2 and SMWWriter, in a MediaWiki extension) to populate Semantic MediaWiki pages with triples, from a snippet of RDF/XML (Thanks to Egon Willighagen for the RDF-ized NMRShiftDB data, submitted further below), yay! But ... as you can see, using the full URI:s as wiki names is not a good idea. URI:s as wiki titles is ugly ... and the predicates in this case even got truncated and all treated as the same one, since they had hashes in it, which MediaWiki obviously doesn't allow in titles), so that's the whole background for our talking so much about the "equivalent URI handler" (mentioned here for example), which is thought to be a configurable handler of mappings from URI patterns to (sensible) wiki titles. Also, optimally the same pattern can then be used both on import and export so that the format is kept, allowing to use SMW as a (collaborative) RDF editor! (which is one of the main motivations for my GSoC project).
Well, the hard bits (URI -> Wiki title mapping) remains. Diving in to it now ...
Recent blog posts
- I created a Udemy course on my favourite linux commandline productivity techniques
- My top-languages-per-use-case list
- The smallest pipeable python script
- Vote for ProcessWire to be packaged as a BitNami image
- Calling Java from Python without the JVM startup latency: NailGun and JPype
- New Google+ communities: Bioclipse, Cheminformatics, Semantic MediaWiki
- Don't use Swedish keyboard with vim/screen/bash
- Easier debugging of Go programs on the command line with CGDB
- Profiling and creating call graphs for Go programs with "go tool pprof"
- Python-like generator functions in Go