Bioclipse
Idea: How to store Prolog rules in Bioclipse scripts
Thu, 2009-12-03 16:04 | by Samuel LampaIt just struck me a very simple way of storing prolog code inside Bioclipse scripts, avoiding the need for a separate file containing the Prolog code. This might be very useful when using prolog as a kind of "query language" somewhat analogous to how SPARQL is used.
(Update: Prolog in fact turns out to be more powerful than SPARQL in this regard, as shown by the observation in this blog post, that SPARQL doesn't support backtracking).
The idea would be to simply store the prolog code in Bioclipse JS variable, and create a special manager method that can write such prolog query-code containing variables to a temporary file in the workspace and then just telling Prolog to "consult" that file, thereby "feeding the prolog engine" with the logic to use, from inside Bioclipse scripts.
Performance comparison #2, Simple 13C Spectrum Similarity Search
Thu, 2009-12-03 15:53 | by Samuel LampaProlog
Bioclipse code
var start2 = new Date().getTime();
// js.say(blipkit.queryProlog( [ "findMoleculeWithPeakValuesNear", "100", "[23.3, 23.3, 23.5, 23.5, 26.1, 60.5, 90.0, 132.1, 0]", "Molecules" ] ));
js.say(blipkit.queryProlog( [ "findMoleculeWithPeakValuesNear", "100", "[12.5, 13.8, 23.8, 36.5, 44.3, 78.8, 87.3, 133.8, 0]", "Molecules" ] ));
var elapsed2 = (new Date().getTime() - start2)/1000;
js.say("Total time for finding molecule by shift values (Near-search): " + elapsed2 + " s");File based RDF storage in Pellet, first tests
Tue, 2009-11-24 17:32 | by Samuel LampaAs reported in a previous blog post, I ran into java stacksize errors when importing large amounts of data into pellet. Pellet was using just the in-memory Jena RDF store, which obviously puts limits on the amount of data it can handle.
Jena offers other options for RDF storage though, including SDB for SQL backends, and TDB for a pure Java file based storage.
Initial performance comparison: Pellet vs Prolog in Bioclipse
Mon, 2009-11-23 11:41 | by Samuel LampaI started with some initial performance testing for RDF data, between pellet an prolog, which are now both available integrated in Bioclipse.
Bioclipse manager method to take arbitrary number of arguments
Tue, 2009-11-17 11:55 | by Samuel LampaI needed a Bioclipse manager method that could take an arbitrary number of arguments, (for a general purpose prolog method mapper). Through a useful discussion with jonalv, we figured out that there exists at least one working way of doing this, while there are a number of ways that do not work across both the Rhino/JavaScript though they work in Java alone.
A usage strategy emerges
Thu, 2009-11-12 17:31 | by Samuel LampaA strategy for how to work with the Bioclipse/JPL/Prolog/Blipkit combination I'm setting up, is becoming clear.
The main idea with Bioclipse, as well as with having a prolog engine available in it, is for flexible and "interactive" knitting together of knowledge. One of the main questions regarding how to use a Bioclipse/JPL/Prolog/Blipkit combination, has been where to put the bulk of knowledge integration/reasoning code? There would in principle be three options for that:
- Bioclipse (Javascript environment)
- The Blipkit-Prolog/Bioclipse integration plugin (Java code, a.k.a. "Manager methods")
- The prolog engine (As a prolog file)
How to deal with rdf namespaces (does not work well with JPL)
Mon, 2009-11-09 18:09 | by Samuel LampaI had the problem that in JPL (The java Prolog API) you cannot use namespaces before term (atoms or variables etc.) names, like so:
prologFunction( ns:'atom' ).
The best solution would be to have some kind of "namespace-like" support in the JS console of Bioclipse instead. One easy thing one can do is to just create a simple function that appends the long preceding URL, so a JS Example could be:
function molid ( term ) {
return "http://pele.farmbio.uu.se/nmrshiftdb/?moleculeId=" + term;
}
blipkit.queryRDF(molid("234"),"X","Y");Testing out querying Prolog from Bioclipse
Sun, 2009-11-01 00:20 | by Samuel Lampa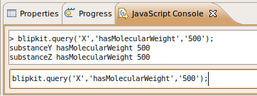
My project has been more or less on hold for around a week because of exams and other stuff. Looking forward to getting some concrete things done now. While still reading up a bit on OWL, I've started taken the first steps of the prolog/blipkit integration with a simple method for querying a prolog on the form "subject, a predicate, and an object".
Plugin development for Bioclipse - from scratch
Thu, 2009-10-08 10:51 | by Samuel LampaI switched laptop recently, so I needed to set up my development environment for Bioclipse 2.2 plugin development from scratch. Since the instructions for how to do this are spread over a couple of blogs and the wiki, I used the occasion to create an integrated howto, for my own documentation as well as for anyone interested.
Initial observations on the difference between Prolog based reasoners (Blipkit) and DL-reasoners (Pellet)
Wed, 2009-09-23 12:45 | by Samuel Lampa- Pellet is coupled with a Datalog reasoner.
1. Sirin E, Parsia B, Grau BC, Kalyanpur A, Katz Y: Pellet: A practical OWL-DL reasoner. World Wide Web Internet And Web Information Systems 2007, 5:51-53. - Datalog is a subset of Prolog
- Jena too seems to have a datalog implementation, according to http://en.wikipedia.org/wiki/Datalog
- DLP is the intersection of Horn logic and OWL, where as SWRL is (roughly) the union of them. <fn>1. Parsia B, Sirin E, Grau BC, Ruckhaus E, Hewlett D: Cautiously Approaching SWRL.
Recent blog posts
- I created a Udemy course on my favourite linux commandline productivity techniques
- My top-languages-per-use-case list
- The smallest pipeable python script
- Vote for ProcessWire to be packaged as a BitNami image
- Calling Java from Python without the JVM startup latency: NailGun and JPype
- New Google+ communities: Bioclipse, Cheminformatics, Semantic MediaWiki
- Don't use Swedish keyboard with vim/screen/bash
- Easier debugging of Go programs on the command line with CGDB
- Profiling and creating call graphs for Go programs with "go tool pprof"
- Python-like generator functions in Go