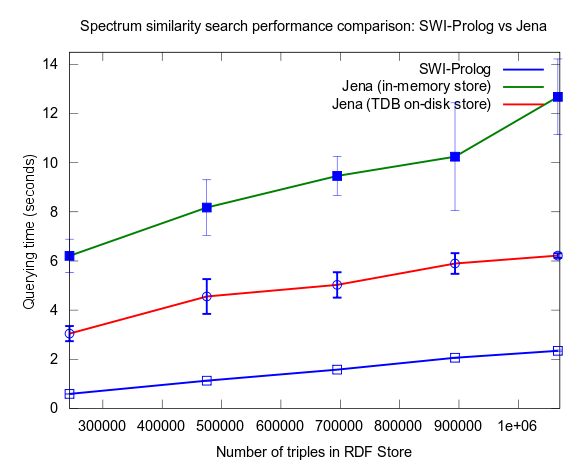
On larger datasets and more peaks in the query, Prolog is the fastest
In a previous performance test I compared a NMR Spectrum similarity search programmed in Prolog and run in SWI-Prolog integrated in Bioclipse, against a SPARQL Query doing the same task, run in Jena, and Pellet, also integrated in Bioclipse.
In that test Jena was the fastest, outperforming Prolog. The test had flaws though, as reported here with new tests added, though these new results were still not giving a clear winner.
This changed when I turned to larger datasets, testing on the range 2000-25000 spectra (where 25000 spectra corresponds to around a million RDF triples), instead of 10-100, which is a lot closer to the size of all spectra in NMRShiftDB (36419 searchable spectra as of March 29, 2010). I also used 16 instead fo 3 peak shift values in the search query. When testing with these changes, Prolog clearly took the lead.
(Bioclipse scripts, including the SPARQL Query, and the Prolog code, attached. See below).
This time I also included tests with Jena using both the in-memory RDF Store, and the Jena TDB disk based one. Interesting is that Jena run against the TDB disk based store is about double as fast as against the in-memory store! (I had to exclude the combination Pellet/TDB store, as it didn't complete for more than an hour, after which I stopped the run.)
To be noted, in these tests I did also take more measures as to avoid memory and/or caching related bias. For example, I did not rerun tests shortly after each other in a loop, but restarted Bioclipse after each run. This kind of testing took a lot more time, and I have so far only had time to do three iterataions for each specific size of dataset. Error bars, indicating the standard deviation, are included though to give an idea of the variation among the three. Hopefully I will have time to complement with a few more runs per measure point.
See figures below for results. I've included one figure where Pellet is included, and one where it is skipped, in order to get a zoom in on the Jena/Prolog difference.
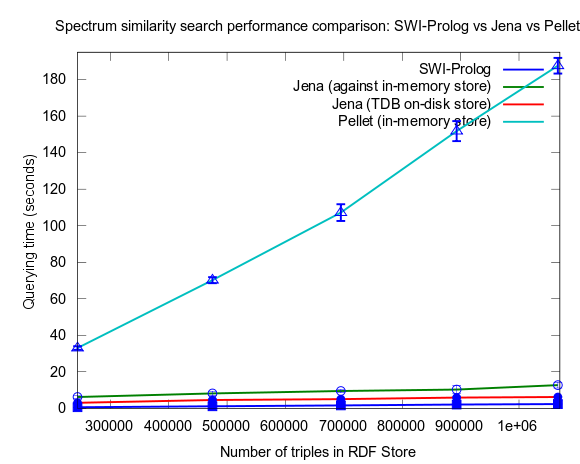
...and, Pellet excluded:
| Attachment | Size |
|---|---|
| NMR.Swipl_.OneAtATime.js.txt | 4.33 KB |
| NMR.Jena_.TDB_.OneAtATime.js.txt | 4.23 KB |
| NMR.Jena_.InMem_.OneAtATime.js.txt | 4.17 KB |
| NMR.Pellet.InMem_.OneAtATime.js.txt | 4.15 KB |
Recent blog posts
- I created a Udemy course on my favourite linux commandline productivity techniques
- My top-languages-per-use-case list
- The smallest pipeable python script
- Vote for ProcessWire to be packaged as a BitNami image
- Calling Java from Python without the JVM startup latency: NailGun and JPype
- New Google+ communities: Bioclipse, Cheminformatics, Semantic MediaWiki
- Don't use Swedish keyboard with vim/screen/bash
- Easier debugging of Go programs on the command line with CGDB
- Profiling and creating call graphs for Go programs with "go tool pprof"
- Python-like generator functions in Go